
Garbage In, Gospel Out : Unlocking the Secrets of Reliable Insights with Dirty Data
Uncovering the truth


Garbage In, Garbage Out (GIGO)
We are familiar with the adage Garbage in, garbage out(GIGO)that became popular in the twentieth century. Garbage in, garbage out means faulty input yields faulty results.
With respect to data, Garbage in, Garbage out means dirty data in, dirty data out. Dirty data is also known as rogue data, bad data, or low quality data.
Garbage In, Gospel Out
There is another catchphrase “Garbage in, gospel out.” As stated by Dan Morris, the founding principal of Wendan Consulting, this slogan reflects the belief by management and IT that enough data (even though of not good quality) will, none the less, produce great reports, analytics and decisions.
Garbage In, Gospel Out — Unlocking the Secret?
The question is, is it possible to have Garbage in, gospel out, that is, can we get reliable insights with dirty data being fed into the system. This is possible in two cases:
While input data is of bad quality, the data is good enough for the insights that we want to draw from them. For example, if we would like to find out the yearly sales figures. However, the sale dates have been recorded incorrectly, such that the day and the month are not recorded correctly, but the year is recorded correctly. Since we do not need daily or monthly sales figures, but yearly sales figures, we would still be able to get the correct results, as the year stored as the part of the sale date is correct.
In some cases, it is possible to fix the data and this process is known as data cleansing or data cleaning. The first step is to assess the data, find then look for patterns in the data to see what is wrong with the data, and whether it can be fixed, and finally devising rules to clean or fix the data.
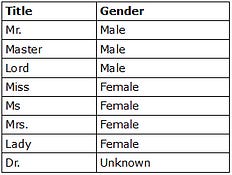
For example, say you would like to study the consumer marketing trends by gender. However, while the gender data is missing for 70% of the data records, the title is captured correctly for 95% of the customers. With the title-gender mapping rules in Table 1, it is possible to derive the gender data for almost all the data. However, note, for example, the title “Dr.” is applicable to both male and female, and hence it is not possible to derive gender using “Dr.”. However, one can still scan the names of the remaining customers and make an educated guess whether the gender is female or male.
Concluding Thoughts
While capturing good quality data at the source is always desired, it is not always possible to ensure the same. However, it also not appropriate to think that a large amount of data will overcome the deficiency in its values. It is important to assess the data to understand their fitness for use and shortcomings, before using the same to derive insights and make decisions.
Hope you found this article useful! If you have any questions or any inputs you would like to share, leave a comment here or connect on LinkedIn.
Future articles on data will focus on data quality dimensions, data quality assessment, and other aspects of data quality and data governance.
To learn more about data quality, data profiling, including how to measure data quality dimensions, implement methodologies for data quality management, data quality strategy, and data quality aspects to consider when undertaking data intensive projects, read Data Quality: Dimensions, Measurement, Strategy, Management and Governance (ASQ Quality Press, 2019).