
What Data Quality (DQ) Approach Do I Use To Manage Dirty Data?


What is Dirty Data and What Is Its Impact?- In a Nutshell
Dirty data, also known as rogue data, bad data, or low-quality data, are data that are inaccurate, incomplete, outdated, invalid, irrelevant, corrupt, duplicated, insecure, or inconsistent.
The term "dirty data" is not just an emphatic metaphor but a matter of great concern, given the magnitude of adverse financial and non-financial impacts that can be associated with it. As per an IBM survey in 2016, dirty data is estimated to cost the US economy over $3 trillion every year.
Why Do We Have the Dirty Data Problem?
Why does data get dirty?
Does data get dirty only at the point of entry?
Data has often been compared to water. Dirty data is like dirty water. Think of the water in the river. The water in the river might be pure where it starts in the mountainous regions, after the ice has melted. On the other hand, it can get contaminated at the source itself. However, as the water flows down, it certainly gets dirtier, and by the time it reaches the sea or ocean, it is quite polluted (see figure above).
It is not always possible to stop bad data from entering the system in the first place. Dirty data can get into an organization at the point of entry or at the source itself. For example, there might be a typographical error in the data that is entered through the webforms. But say the data was entered correctly at the source. Does that mean that the data stays correct? The answer to this question is, data is quite a traveller, and there are several touchpoints that can corrupt data too.
For example, say customers in an online retail store type their names and addresses through the webform, which are then stored in the operational data store. It is then provisioned through another system to the enterprise data warehouse.
However, while the operational store data model has a country field with a length of 100 characters, the intermediate system only has an ISO country code field with a length of three characters. Unfortunately, the analyst and designer have overlooked this discrepancy and have not set any business rules to map the country name entered to the three-character ISO country codes. In the absence of rules to map the country name to the country code, the first three characters of the country name entered by the user get stored in the intermediate system database.
So let us look at how these country entries look in the webform, the operational data store, and the intermediate system database.
In the above table,
The first entry is "Australia", and the same gets stored in the operational data store. The first three characters, that is, "Aus" get stored in the intermediate system database. However, since "AUS" is the 3 character ISO country code for "Australia", the data is good if you don’t take the case into consideration.
The second entry is "Austria", and the same gets stored in the operational data store, and the first three characters, that is, "Aus" get stored in the intermediate system database. However "Aus" is not the 3-character ISO country code for "Austria". While country data is clean when entered by the user and also clean in the operational data store, it gets dirty in the intermediate system database.
The third entry is "United States", and the same gets stored in the operational data store, and the first three characters, that is, "Uni" get stored in the intermediate system database. However "Uni" is not the 3 character ISO country code for "United States". While country data is clean when entered by the user and also clean in the operational data store, it gets dirty in the intermediate system database.
The third and fourth entries have typos and are dirty at the point of entry itself, as well as in the operational data store and the intermediate system database.
How Do You Deal With Dirty Data?
There are a number of approaches to dealing with dirty data.
A preventive approach stops bad data from entering the system;
Using a reactive approach to fix bad data after it has entered the system.
Hybrid approach (a mix of preventive and reactive measures): preventive measures to prevent bad data from happening as much as possible, and reactive approaches to fix bad data once discovered.
What data quality (DQ) approach do you use to manage dirty data?
I ran a 7-day poll in the TDWI: Analytics and Data Management Discussion Group, a data-focused group on LinkedIn that has close to 80,000 data quality and data governance practitioners, and advocates across the globe, with the very same question, and the responses are as shown in the screenshot below.
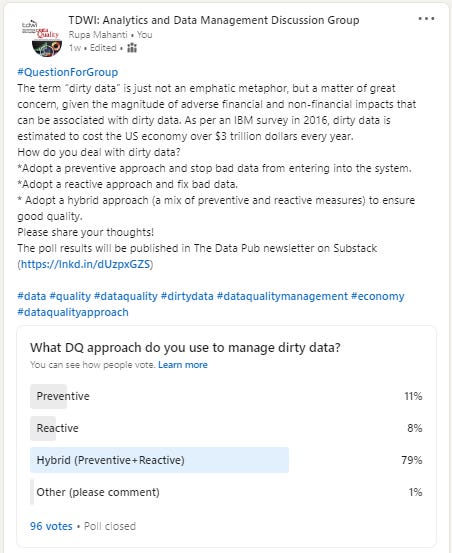
The poll closed at 96 votes from data quality, data governance, and BI professionals, and details are as follows:
79% chose the option—“Hybrid (Preventive+Reactive),”
11% chose the option—“Preventive,”
8% chose the option—“Reactive,”
A tiny percentage (1%) chose the “Other (please comment)” option.
It is best to use a hybrid approach to ensure high-quality data. Use a preventive approach to stop bad data from entering the systems where possible. However, even with robust processes, bad data is bound to creep into an organization’s digital ecosystem and hence a preventive approach will not be sufficient. Once bad data happens, reactive approaches need to be used to treat the data.
Let’s illustrate the same using the country name entry example that we used to illustrate dirty data earlier in this article.
The third and fourth country entries could have been prevented by having a drop down list of countries for the user to choose from instead of having the user to type the country name. However, once the bad data has entered the system, these entries need to be corrected using an authoritative source of data.
With the second and third entries, reactive measures, that is, business rules need to be implemented to map the country name to the ISO Country code and correct the bad data.
Concluding Thoughts
There is no one size fits all approach to deal with dirty data. Data like water can be contaminated at the source itself and as it travels through the ecosystem and the pipelines. While taking preventive measures such as validation of data entry, introducing controls, and training data entry operators to ensure that dirty data does not enter the digital ecosystem is one of the approaches to having good quality data at the source, once dirty data enters the digital ecosystem, a reactive approach to treating the data is the only way to fix the data. Usually, a hybrid approach that is a mix of proactive, preventive and reactive approaches needs to be taken to deal with data quality issues.
To learn more about data quality, including how to measure data quality dimensions, implement methodologies for data quality management, and data quality aspects to consider when undertaking data intensive projects, read Data Quality: Dimensions, Measurement, Strategy, Management and Governance (ASQ Quality Press, 2019). This article draws significantly from the research presented in that book.
If you have any questions or any inputs you want to share, comment here or connect on LinkedIn.
Biography: Rupa Mahanti is a consultant, researcher, speaker, data enthusiast, and author of several books on data (data quality, data governance, and data analytics). You can connect with Rupa on LinkedIn or Research Gate (Research Gate has most of her published work, some of which can be downloaded for free).